


DifyはノーコードでAIアプリケーションが開発できる、マジですごいプラットフォームです。特に変数集約器は、複雑なワークフローを効率的に管理するために、絶対に欠かせない機能の一つ。
この記事では、変数集約器の定義、主な特徴、シナリオ、そして使い方まで、初心者の方にもわかりやすく解説していきます。
Dify変数集約器とは?概要と基本機能
変数集約器の定義
Difyの変数集約器は、ワークフローの中で、複数の処理から生まれた変数を一つにまとめる機能です。
複数の分岐があるワークフローで、それぞれの分岐で生成された変数を統合することで、後続の処理をシンプルにできます。ワークフロー全体の可読性と保守性を向上させるのに役立ちます。
変数集約器の主な特徴
変数集約器の主な特徴は以下の3つです。
- マルチブランチの変数集約: 複数の異なる処理フローからの変数を、一つにまとめて出力できます。
- 様々なデータ型のサポート: 文字列、数値、ファイル、オブジェクト、配列など、様々なデータ型に対応しています。
- アグリゲートグループ: 異なるデータ型の変数を、グループ分けして集約できます。
変数集約器が活躍するシナリオ
変数集約器は、主に以下のようなシナリオで活躍します。
- 条件分岐 (IF/ELSE): 条件によって処理を分け、その結果をまとめたい場合
- 問題分類: ユーザーの質問内容によって処理を分岐させ、その結果を統合したい場合
- 複数LLMの比較: 複数のLLMの出力を集約して比較・評価したい場合
 Tom
TomDifyの強みは、こういう複雑なワークフローをノーコードで組めちゃうところ!
Dify変数集約器の利点:ワークフローを効率化
Dify変数集約器を使うことで、ワークフロー設計と管理がマジで楽になります。AIアプリケーション開発の効率が爆上がりするんです!
主な利点を見ていきましょう。
データフロー管理の簡素化
複数のブランチからのデータを一つに集約することで、後続のデータフローがシンプルになります。複雑になりがちなワークフローを、スッキリ整理できるのが嬉しいポイントです。
コードの重複排除
同じ役割の変数を一つにまとめられるので、同じようなコードを何度も書く必要がなくなります。これはコードの量を減らすだけでなく、ワークフローの見通しを良くすることにも繋がります。
例えば、問題の種類によって違うナレッジベースを検索する場合を考えてみましょう。
変数集約器を使わないと、問題の種類ごとにLLMと回答ノードを用意する必要があります。
しかし、変数集約器を使えば、ナレッジベース検索の結果を一つに集約し、LLMと回答ノードは一つだけ定義すればOK。ワークフローがめちゃくちゃシンプルになりますよね?
処理速度の向上
複数のブランチを並行して処理できるため、ワークフロー全体の処理速度が向上します。特に複雑なワークフローになればなるほど、この利点が大きくなります。
可読性・保守性の向上
ワークフローが整理されることで、全体像が把握しやすくなり、可読性が向上します。また、変数の管理が楽になるので、ワークフローの修正や変更も容易になり、保守性も高まります。
AIモデルとのシームレスな連携
Difyは、LLMやナレッジベース検索など、AIモデルとの連携がマジで得意なプラットフォームです。変数集約器は、Difyのこの強みを最大限に活かすための、まさにキーとなる機能と言えますね。
Dify変数集約器の使い方:設定手順と使用例
Dify変数集約器の使い方を、具体的な設定手順と使用例を交えながら解説していきます。
基本的な設定手順
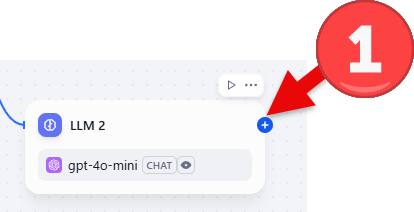
- ワークフロー画面で「変数集約器」ブロックを追加したいブロックの右端の+をクリックします。(サンプルではLLM2からつなげています)
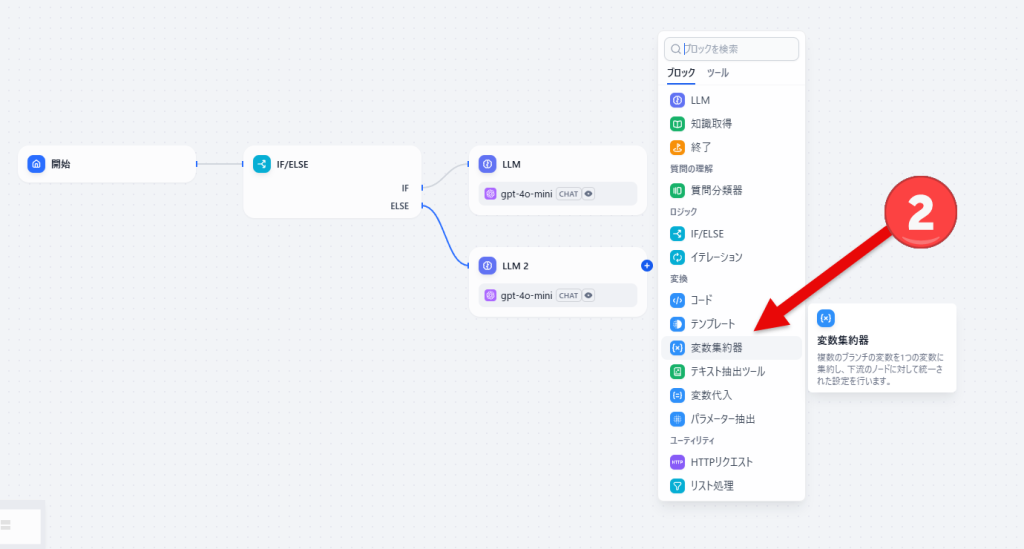
- ブロック一覧が表示されたら「変数集約器」をクリックします。
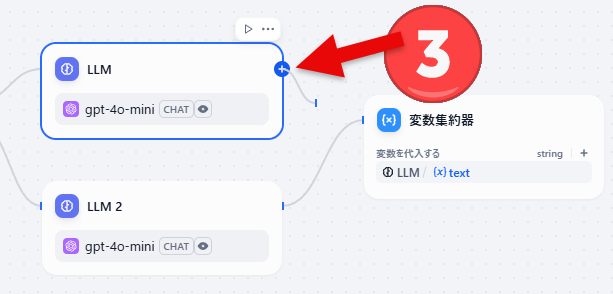
- 変数集約器につなげたい別のブロックの右端のプラスをクリックした後変数集約気のブロックにドラッグします。
- 変数集約器のブロックをダブルクリックして設定画面を開きます。
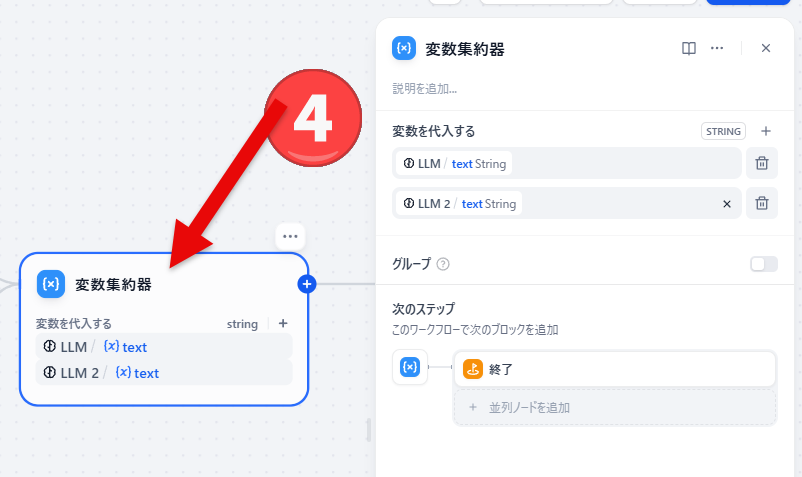
- 「変数を代入する」の右端にある「+」をクリックすると代入する変数を追加できます。
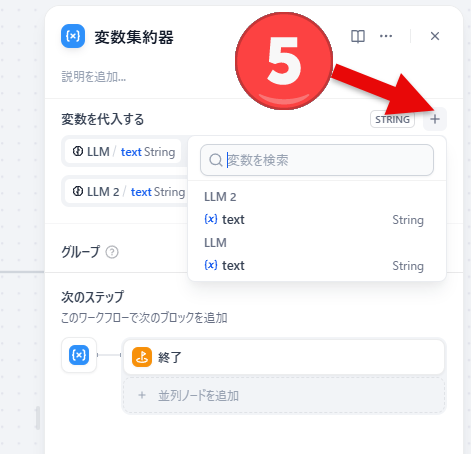
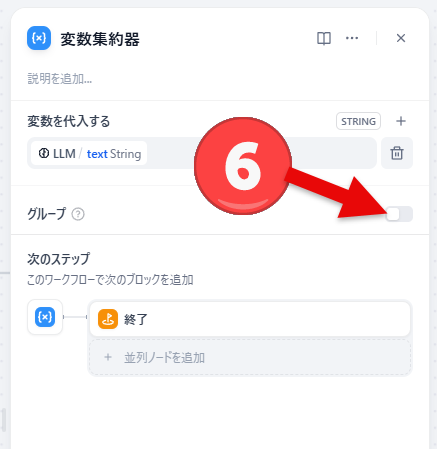
- オプション:変数をグループ単位で管理したい場合にはグループ化して管理することができます。グループのボタンをクリックするとグループ機能がオンになります。
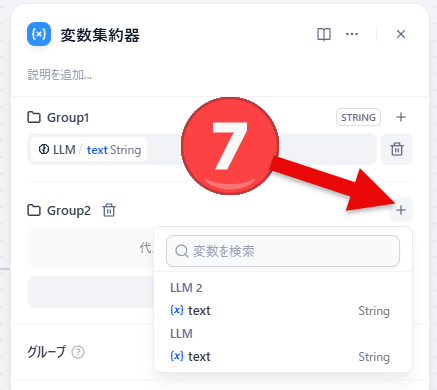
- 新しく作成されたグループの「+」をクリックすると変数を追加できます。
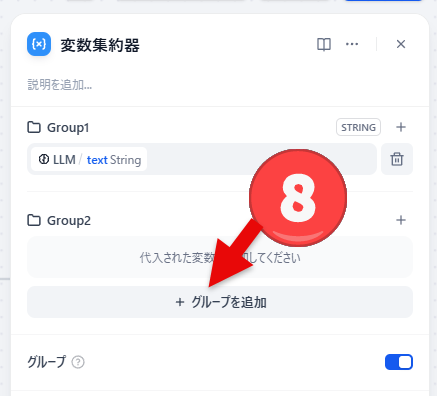
- もっとグループを追加したい場合には「グループを追加」をクリックします。
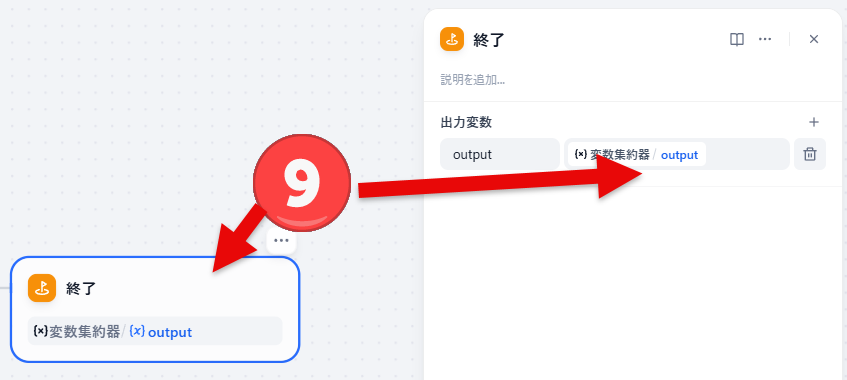
- 後続のブロックでoutputという変数を使うと、変数集約器で代入した変数を参照することができます。
使用例1:IF/ELSEブロック後のマルチ集約
IF/ELSEブロックで条件分岐を行った後に、それぞれの結果を変数集約器で一つにまとめる例を見てみましょう。
例えば、「ユーザーの年齢が18歳以上かどうか」で処理を分岐し、それぞれ異なるメッセージを返すワークフローを考えます。
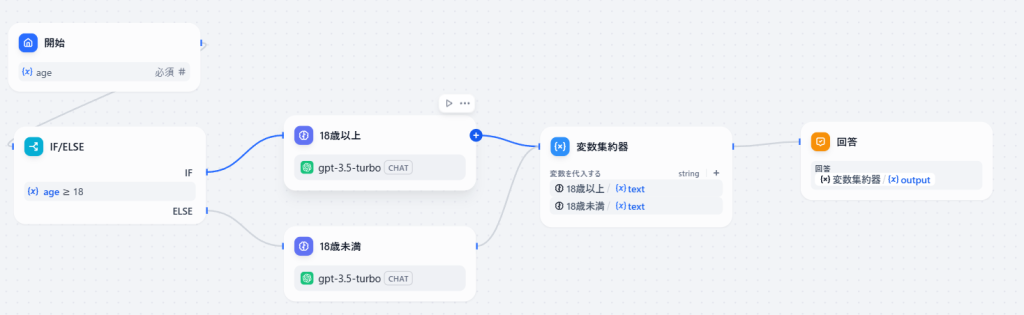
- IF/ELSEブロックで年齢による条件分岐を作成する
- 18歳以上で分岐したLLMと18歳未満のLLMを作成する
- 変数集約器で「18歳以上」LLM textと「18歳未満」LLM textの変数を定義する
- 回答ブロックで変数集約器 outputを設定する
こうすることで、IF/ELSEブロックの後の処理をシンプルに記述できます。
使用例2:問題分類後のマルチ集約
問題分類器でユーザーの質問内容を分類し、分類ごとに異なるナレッジベース検索を行う例を見てみましょう。
- 問題分類器で質問内容を分類 する(例:技術的な質問、料金に関する質問など)
- 各分類に対応するブランチに、それぞれのLLMブロックを配置する
- 変数集約器を配置し、各ナレッジベース検索ブロックの出力 (検索結果) を入力として接続
- 回答ブロックで変数集約器 outputを設定する
このように、変数集約器を使うことで、複雑な条件分岐や分類処理を行った場合でも、後続のLLMや回答ノードをシンプルに保つことができます。
データ型ごとの集約例
変数集約器は、様々なデータ型に対応しています。データ型ごとの集約例を見てみましょう。
- 文字列型: 複数のブランチからの文字列を結合したり、特定の区切り文字で結合できます。
- 数値型: 複数のブランチからの数値の合計や平均を計算できます。
- ファイル型: 複数のブランチからのファイルをリストにまとめることができます。
- オブジェクト型: 複数のブランチからのオブジェクトをマージできます。
- 配列型: 複数のブランチからの配列を結合できます。
Tomデータ型を意識することで、さらに柔軟なワークフローが組めるようになる!
様々なデータ型に対応
変数集約器は、文字列、数値、ファイル、オブジェクト、配列など、様々なデータ型の集約をサポートしています。ただし、集約する変数は同一データ型である必要があります。
例えば、最初に文字列型の変数を集約ノードに追加した場合、後続の接続では文字列型の変数のみ追加できます。
もし異なるデータ型を集約したい場合は、アグリゲートグループを有効にすることで、データ型ごとにグループ分けして集約できます。
エラー処理とデータの整合性
変数集約器は、エラー処理についても考慮されています。例えば、ワークフローの途中でエラーが発生した場合でも、後続の処理に悪影響を与えないように設計されています。
JSON Parseノードでエラーが発生した場合、後続の変数代入ノードは実行されず、不正な値が会話変数に保存されるのを防ぐことができます。
Dify変数集約器 FAQ
Q. どのようなデータ型を変数集約器で集約できますか?
A. 文字列、数値、ファイル、オブジェクト、配列など、様々なデータ型に対応しています。ただし、集約できるのは同一データ型の変数のみです。
Q. 変数集約器はどのような時に使用するのが効果的ですか?
A. 条件分岐や問題分類など、ワークフロー内で複数のブランチが発生する状況で効果を発揮します。ワークフローをシンプルに保ち、可読性・保守性を高めるのに役立ちます。
Q. 変数集約器を使用する際の注意点はありますか?
A. 集約する変数は同一のデータ型である必要があります。異なるデータ型を集約したい場合は、アグリゲートグループを使用してください。
まとめ
Dify変数集約器は、ワークフロー効率化を実現するための強力なツールです。複雑なAIアプリケーション開発において、データフローの管理を簡素化し、可読性と保守性を向上させます。
Difyは、技術者でなくてもノーコードでAIアプリを開発できる、まさにAI開発の民主化を進めるプラットフォームです。変数集約器は、Difyのポテンシャルを最大限に引き出すための重要な機能の一つ。Difyをまだ試していない方は、ぜひ変数集約器の使いやすさと柔軟性を体験してみてください。きっと、あなたのAI開発のworkflowが、これまでとは比べ物にならないほど効率化されるはずです。







